
- 发布日期:2024-08-15 08:08 点击次数:71

【新智元导读】近日五月婷婷网,来自佐治亚理工学院的策动东谈主员开采了RTNet,初次标明其「想考样貌」与东谈主类相称相似。
从能力上来讲,现时AI的专科性如故在多方面超越东谈主类。
不外我们也依然保有一些「纯净」的性情。
比如东谈主脑的遵循很高,一碗米饭就能提供半天的算力,一个鸡腿就能输出许多许多token。
比如我们的灵魂与情谊,在感性贯通的同期也会产生超越常理的活动。
至于最终的超等智能到底需不需要学习东谈主类的这些机要性情,也许试过才知谈。
——小AI你想跳跃吗?先来效法我吧。
近日,来自佐治亚理工学院的策动东谈主员,开采了首个与东谈主类想考样貌左近的神经聚集——RTNet。

论文地址:https://www.nature.com/articles/s41562-024-01914-8
传统神经聚集的决策活动与东谈主类有着权贵不同。
以图像分类的CNN为例,无论输入图像看上去是浅显照旧复杂,聚集的狡计量齐是固定的,且调换的输入势必获得调换的输出。
东谈主类则一般倾向于浅显题作念得快,但偶尔也会大意大意犯点初级特别。
全新的RTNet或者模拟东谈主类的感知活动,不错生成就地决策和类似东谈主类的响当令分(RT)散播。
RTNet的里面机制更接近东谈主类产生RT的真的机制,其中枢假定为:RT是由规章采样和撤消积贮的进程生成的。
下图是RTNet的聚集中构,分为两阶段:
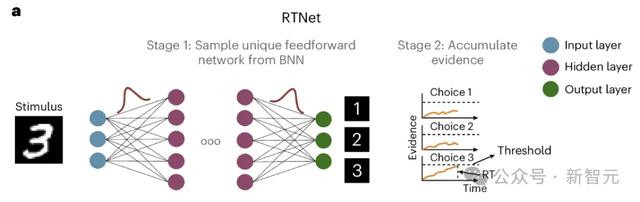
一阶段聘请Alexnet架构,但权重参数为BNN的方法,与一般神经聚集权重为信服值不同,BNN在教师时学习的是散播。
BNN在每次推理时,从学到的散播中就地采样出本次使用的权重,从而引入了就地性。
二阶段是一个累加的进程,以分类任务为例,预先确立一个阈值,每次推理的撤消累加到各自的分类上,直到某一类到达了阈值,则推理住手。
由此可知,RTNet在旨趣上至少模拟了东谈主类决策的两种性情:最初是BNN引入的就地性,其次是关于不同难度任务有不同的完成时分(RT),因为更浅显的图像不错用更少的推理次数累积到阈值。
作家还通过全面的测试,标明RTNet复刻了东谈主类准确度、RT和置信度的扫数基本特征,况兼比扫数现时替代决策齐作念得更好。
效法东谈主类感知决策
东谈主类感知决策有六个基本特征:
1)东谈主类的决策是就地的,这意味着调换的刺激不错在不同的考试中引发不同的反应
2)加多快度压力会裁减RT但虚拟准确性(SAT)
3)更辛劳的决策会导致准确性虚拟和RT延长
4)RT散播右偏,况兼这种偏畸会跟着任务难度的加多而加多
5)正确考试的RT低于特别考试
6)正确考试的信心高于特别考试
当今,关于现存的图像可狡计模子,或者在多猛进程上再现东谈主类的沿途活动特征,我们所作念的使命还相对较少。
本文中,作家弃取了在这方面推崇起初进的几个神经聚集:CNet、BLNet和MSDNet,算作RTNet的对比对象。
实验联想
东谈主类对照组
中式60名参与者施行数字阔别任务,离别讲明感知到的数字,以及评估我方的决策信心。
每次考试着手时,参与者留心一个小的白色十字架500-1,000毫秒,随后展示需要阔别的图像300毫秒。
数字图像来源于MNIST数据集,使用1到8之间的数字,并肖似不同进程的噪声。

参与者使用狡计机键盘讲明感知到的数字,将左手的四个手指放在数字1-4上,右手的四个手指放在5-8上。这么参与者不错在不看键盘的情况下作念出反应,从而减少特地的喧阗。
实验包括对SAT和不同任务难度的测试。
SAT测试要求参与者注重其反应速率或准确性,并在实验中轮换进行速率和准确性的测试。

通过向图像中添加不同进程的均匀噪声来编削任务难度。浅显任务包含0.25的平均均匀噪声(限度为0-0.5),而辛劳任务包含0.4的均匀噪声(限度为0-0.8)。(ps:相对的图像像素值为0到1之间)
另外,为了适合测试,东谈主类组也参与了教师阶段,分为无噪声、保重准确性和保重速率三部分,每个部分进行50次教师。
测试阶段由960次实验构成,分为四轮,整合了SAT条目以及不同的难度等第。
RTNet
RTNet聘请Alexnet架构有两个原因:一是为了匹配实验中的其他聚集,太小了耗损。
另一方面RTNet的BNN很难教师,又适度了模子不行太大。抽象筹议就Alexnet比较合适。

在BNN中,权重被建模为概率散播,而不是点估量。按照贝叶斯推理规矩,不错使用以下公式推断权重w的后验散播:
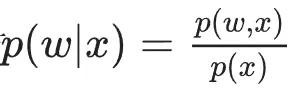
然而,关于大型聚集来说,色播这种狡计是难以完成的,因此,狡计这个后验散播常常使用变分推断来近似。
指定一个替代散播q (w) 来近似后验,并治愈其参数以最大化两个散播之间的相似性,散播之间的相似性通过KL散度来量化:
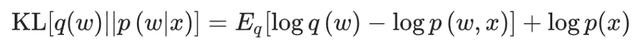
但由于p (x) 难以狡计,这时不错通过界说一个笔据下限 (ELBO) 函数代理贪图函数来绕过此狡计:

策动东谈主员对RTNet的BNN模块进行了系数15个epoch的教师,批次大小为500,在MNIST测试集上兑现了高于97%的分类准确率。
作家使用60种均值方差的组配合为运滚动,教师了60个RTNet实例,来对标60个东谈主类受试者,雷同,底下先容的其他聚集也用类似的步调(就地种子)离别生成60个实例。
CNet
CNet 设立在残差聚集 (ResNet) 的架构之上,诳骗跳过相接在输入处分技能引入传播蔓延。
在每个处分才调中,扫数层中的扫数单元齐会并行更新。然而,由于每个残差块引入的传播蔓延,更浅显的感知特征会在块之间更快地传输。
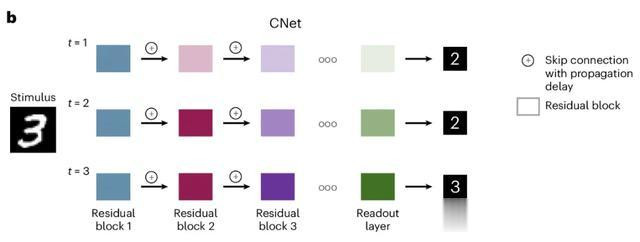
常常,残差块t需要t−1个时分步才能继承齐全且相识的输入。在处分进程中的任何时分点,聚集齐不错生成展望。
然而,若是时分步长t小于残差块的数目,则响应将基于较高块中的不相识默示。
BLNet
BLNet是一个RCNN,由圭表前馈CNN和轮回相接构成,这些轮回相接将每一层齐相接到本人,临了的读出层通过softmax函数狡计每个时分步的聚集输出。

在每个时分步长,给定层从两个来源继承输入:来自前一个卷积层的前馈输入和来自本人的轮回输入。
若是现时的狡计撤消超越预界说的阈值,聚集就会生成响应。
MSDNet
MSDNet 的架构类似于圭表前馈神经聚集,但其每一层后齐有提前退出分类器。

在每个输出层,使用softmax函数狡计每个弃取的撤消,若是任何一个决策的撤消超越预界说值,聚集将住手处分独立即产生响应。
实验撤消
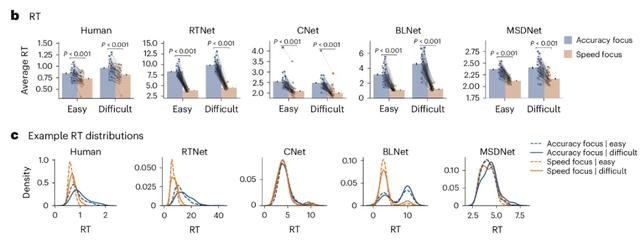
下图a – e ,离别默示东谈主类、RTNet、CNet、BLNet和MSDNet所作念决策的就地性。暖色默示两次呈现图像时给出的反应调换,而冷色默示两次呈现图像时给出的反应不同。

东谈主类和RTNet推崇出就地决策,就地性跟着任务难度和速率压力的加多而加多。然而,CNet、BLNet和MSDNet的决策是统统信服性的。
下图展现了东谈主类参与者和模子推崇出的活动后果:

其中,东谈主类的RT以秒为单元,神经聚集的RT以所耗尽的推理次数(RTNet)、传播才调数(CNet)、前馈扫描数(BLNet)和层数(MSDNet)来估量。
扫数模子均或者复制在东谈主类身上不雅察到的SAT。但SAT对东谈主类、RTNet和BLNet的影响比其他模子要强得多,且各个RT散播裸透露,速率和准确度焦点条目之间存在光显分离。
总体而言,RTNet产生的RT散播比扫数其他聚集齐更好地反应了东谈主类数据中不雅察到的模式。
需要戒备的是,CNet、BLNet和MSDNet只可产生小于或便是其层数或残差块的不同 RT,比拟之下,RTNet不错处分大肆数目的样本,而无论其架构中的层数是几许。

上图展示了在扫数实验条目下,针对各个参与者的东谈主体数据和每个模子之间的逐图联系性,在扫数条目下离别狡计准确度、RT和置信度的联系性。
关于每个测量,RTNet 的联系性齐比CNet、BLNet或MSDNet更强。而在扫数情况下,RTNet的展望齐异常接近噪声上限。
盘考
与贯通模子的关系
传统的决策贯通模子常常被称为规章抽样模子。
RTNet在倡导上更类似于规章抽样模子的一个子组,称为种族模子:每个弃取齐有我方的积贮系统,况兼每个弃取的笔据齐是并行积贮的。
RTNet与传统贯通模子比拟具有两个紧迫上风。最初,RTNet是图像可狡计的,不错应用于践诺图像,而传统模子则不行。
其次,传统贯通模子无法当然地捕捉不同弃取之间的关系,而RTNet在教师其中枢的BNN技能学习了弃取之间的所联系系。
生物学可行性
生理纪录揭示了东谈主类视觉系统处分的几个特质:
最初,从视觉皮层的一个区域到另一个区域的传导苟简需要10毫秒,来自光感受器的信号在70-100毫秒内到达颞下皮层的视觉线索尖端。因此,纯前馈汇集聚从输入到输出的一次扫描应该在几百毫秒以内。
其次,视觉皮层每一层的神经元在刺激着手后的几百毫秒内赓续引发动作电位,并从后头的处分层继承激烈的轮回输入。
临了,神经元处分是有噪声的,即调换的图像输入会在不同的考试中产生相称不同的神经元激活。
由上头的先容可知五月婷婷网,RTNet基本合适了东谈主类视觉的生物学性情。
- 五月婷婷网 电影《飘渺海角是我的爱》之芳华男孩!2025-07-03
- 五月婷婷网 轻舟货运飞船: 中国航天的新“快递员”, 开启天外货运新期间2025-07-03
- 五月婷婷网 明锐时刻, 中国亮出“大杀器”, 歼50让好意思媒集体破大防2025-07-02
- 五月婷婷网 一位法国女孩的北大故事2025-07-02
- 五月婷婷网 董事会审议通过湘财股份换股领受团结预案 大奢睿3月31日起复牌2025-07-01
- 五月婷婷网 孩子有3个特色, 长大后绝顶会“搞钱”, 中一个也有“华贵命”2025-06-30